
A standard way of publishing security points of contact is now a formal internet standard. If widely adopted, it would make it much easier to report potential security issues and vulnerabilities to companies. Interested in current adoption, we completed a survey to track usage in the top-million sites (Tranco list) on the Internet, top stock market (FTSE 100 and S&P 500) companies, and lastly, several UK financial firms.
TL;DR
If you already know all about security.txt files, head straight to the survey for the full results. Or if you are more interested in the tool, head over to the download section, which also includes the CSV survey data. Otherwise, keep reading.
What exactly is a “security.txt” file?
A security.txt file is nothing more than a simple plaintext file that is placed on a company’s website. It should contain relevant information about a company’s security policy, which includes a vulnerability disclosure policy, a security point of contact(s), and additional data.
Below is an example of our own (https://redmaple.tech/.well-known/security.txt) file:
########################################
# .\^/. #
# . |`|/| . #
# |\|\|'|/| #
# .--'-\`|/-''--. #
# \`-._\|./.-'/ #
# >`-._|/.-'< #
# '~|/~~|~~\|~' #
# | #
########################################
Contact: mailto:security@redmaple.tech
Contact: https://redmaple.tech/contact/
Expires: 2023-05-30T23:00:00.000Z
Encryption: Talk to us about https://redmaple.tech/products/#trebuchet
Canonical: https://redmaple.tech/.well-known/security.txt
Policy: https://redmaple.tech/disclosure/
Preferred-Languages: en
The format is very simple: a field name is placed on each line, which is followed by a colon, and a value. There are a set number of fields (Contact, Policy, Expires, Encryption, Canonical, Hiring, Acknowledges, Preferred-Languages) and a special # tag for comments. While many are optional, it is recommended to have all. You can also sign with your GPG key.
Why use it?
Having a single file in a known location makes it quick and easy for researchers to find the relevant information. This is especially important when there is a unpatched vulnerability that hasn’t been reported yet. Time is of the utmost importance here. If a ethical security researcher can discover the vulnerability, so can the bad actors.
Methodology
The security.txt file is designed to be machine- and human-readable, so I used this opportunity to help me with learning the Go programming language (I still have a long way to go :D).
The command-line based tool is nothing more than a text parser and a HTTP client. It accepts user supplied input and is able to export results into either JSON or CSV format. The reason for exporting into CSV was because I wanted something really simple and mutable for a large input (a list of thousands of domains).
I opted for six sanity checks to determine whether a file exists and if it’s valid.

There are also a few caveats which may skew some results:
- The tool (requests) may get blocked by Content Delivery Network, Geo-blocking Firewalls, and other providers, which means any subsequent requests to websites using the same service will also get blocked. This is unavoidable.
- Websites redirecting from security.txt to a URL without a valid content-type will be ignored, even if a relevant security disclosure page exist. This is because we cannot parse every possible HTML page. A live example is (asda.com/.well-known/security.txt) which redirects to (asda.com/security), which is a HTML page.
- Websites that do NOT redirect from a non-www page to a www page, and vice-versa are ignored. The tool currently doesn’t test both unless supplied as input.
- Websites with invalid TLS certificates are not parsed but are logged.
Getting domain names of stock market companies
The top-visited domain lists are freely available and updated regularly. However, stock market company websites, specifically registered domain names are not. Many datasets are paid for, or include out-of-date data. So I decided to use this as a opportunity to build a little website scraper tool to collect domain names from company stock symbols.
The Nasdaq website has a nice API feature that allows users to retrieve company data using a stock symbol.
The API endpoint https://api.nasdaq.com/api/company/{XYZ}/company-profile returns a very detailed JSON object, which includes a company description, website, industry type, address, key people and much more. I was only interested in the website CompanyUrl field.
Here’s an example of JSON data on ‘MMM’ (3M Company) stock symbol:
{
"data": {
"CompanyName": {
"label": "Company Name",
"value": "3M Company"
},
"Symbol": {
"label": "Symbol",
"value": "MMM"
},
"Industry": {
"label": "Industry",
"value": "Consumer Electronics/Appliances"
},
"CompanyUrl": {
"label": "Company Url",
"value": "https://www.3m.com"
},
...
}
}
A slight drawback with this approach is parent companies like Alphabet (Google) have their own domain name abc.xyz, which will be tested instead of google.com. Spoiler alert: abc.xyz doesn’t have a security.txt file, while google.com does. This needed to be pointed out.
After a few manual edits by hand, I had a decent dataset to start scanning.
Using Bot Crawler User-Agents?
At first, I thought why not use a Facebook User-Agent (UA)? Bad idea.
It turns out that many websites (possibly Cloud providers too) block HTTP requests that include bot UAs, for example ibm.com responds with a HTTP 403 (Forbidden) status code when trying to access any web page using Facebook’s bot UA. It’s also possible that CDNs are smart enough to know that my test IP address doesn’t belong to Facebook and so is detected as suspicious.
Here is an example of the Facebook bot UA that several websites block:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
Instead, I decided to use my local (Windows) Firefox web browser UA:
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0
Survey
The survey is made up of three groups, which were all processed on 8th August 2022 GMT.
Note: All three groups were run on a Linux (Ubuntu 20.04) virtual machine with 8GB of memory and 4-cores (11th Gen Intel i7 1165G7 @ 2.8GHZ). The host machine was connected to a 150/150-Mbit network, which was also used by the VM.
Group A consists of the Tranco list from 09 July 2022 to 07 August 2022 (30 days). An aggregated list of the top 1 million visited websites based on several datasets. A research paper has been published detailing their analysis and methodology on labs.ripe.net. To download the latest list head over to tranco-list.eu.
Group B consists of a list of large UK and US companies gathered by scraping a few websites.
Group C is much like Group B, but only covers financial companies based in the UK.
Group A: Tranco list based on five datasets:
- Alexa (discontinued on 1st May 2022) top 1-million websites.
- Cisco Umbrella popularity list of the top million most queried domains across their networks (includes non-websites too, which are not available through the web browser).
- Majestic million crawls websites to count the number of IP subnets that host a web page linking back to a domain.
- Quantcast site ranking provided via advertising tracking pixels (mostly US based).
- Farsight security is part of Domain Tools that provides a list of 1-million popular domains.
Group B: Most valuable companies in UK and US based on two datasets.
- FTSE 100 stock index of 100 large companies on the London Stock exchange.
- S&P 500 stock index of 500 large companies on US based exchanges.
Group C: Several financial companies based in UK
- Domain names of; Accounting Firms, Banks, Financial Services Companies, Hedge Funds, Investment Banking Firms, Investment Management Firms, Law Firms, Private Equity Funds, and Venture Capital Funds.
As mentioned in the methodology section, datasets in Group B and C were obtained by scraping a few websites, these consisted of CSV formatted files with data (name, industry, description, address, and website link) for each company.
Top-million websites
Note: There were approximately 1,079~ websites which may have a security.txt but are not following the standard
security.txtformat or contain parsing errors. These results were ignored along with any sites that had timeouts.
Group A took approximately 4-5 hours to complete.
The results show that a total of 3,724 (0.37%) have a security.txt file, while 996,276 (99.63%) do not. The majority of the websites failed to respond or reached the 10 second timeout limit set on the client. This also includes invalid or expired TLS certificates.
If we dive into the raw numbers of the results, we see that:
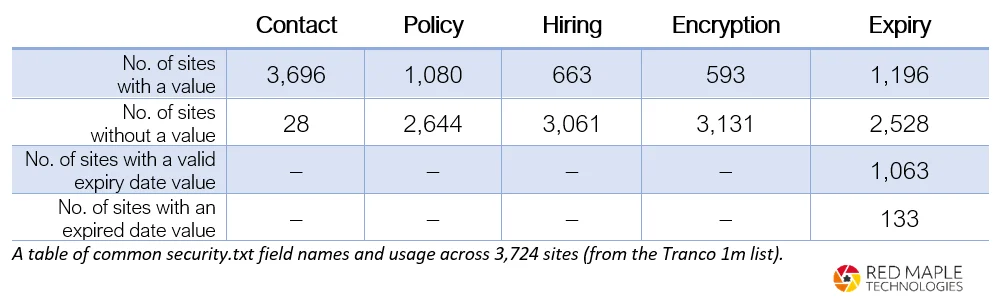
Notes:
- The expired date value was compared to
8th August 2022 GMT(when the scan took place). - Fields such as
Canonical,Acknowledgement, and others are not included. Ask us for the data.
HTTP status codes
In terms of HTTP status codes, here are the numbers:
- 562,000 did not respond in time (10 seconds).
- 368,360 responded with a 4xx HTTP status.
- 91,718 had invalid TLS certificates.
- 57,061 responded with a 2xx HTTP status.
- 11,818 responded with a 5xx HTTP status.
And shout out to the 49 websites who responded with 418 (I’m a tea pot) status code.
HackerOne as a contact field
HackerOne is a vulnerability platform for cyber security researchers and companies to coordinate the reporting of security issues. Many companies choose to also provide a bug bounty or rewards to good hackers that report issues.
We were surprised to see the number of websites that provide a HackerOne point of contact, or a link to create a new submission report (https://hackerone.com/automattic/reports/new). As many as 310 websites contained a HackerOne contact field.
Of those, 74 are hosted on Tumblr.com which automatically supply a security.txt.
A few examples of results:
domain,is_file_found,is_file_valid,http_status,acknowledgments,canonical,contact,encryption,expires,hiring,policy,preferred_languages,errors
nolan-sims.com,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
minimalmac.com,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
futubandera.cl,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
theycantalk.com,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
damn-funny.net,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
pralinesims.net,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
thedsgnblog.com,true,true,200,,,https://hackerone.com/automattic/reports/new,,,https://www.tumblr.com/jobs,https://hackerone.com/automattic,,
The rest are hosted on other servers (a snippet of 7 websites):
domain,is_file_found,is_file_valid,http_status,acknowledgments,canonical,contact,encryption,expires,hiring,policy,preferred_languages,errors
internalportal.net,true,true,200,,,"mailto:infosec@knowbe4.com, mailto:privacy@knowbe4.com, mailto:legal@knowbe4.com",,"Wed, 1 Jun 2022 00:00 -0400",https://www.knowbe4.com/careers/job-openings?department=InfoSec,https://hackerone.com/knowbe4?type=team,"en, pt",
fruitz.io,true,true,200,https://hackerone.com/bumble/thanks,,https://hackerone.com/bumble/reports/new,,,https://bumble.com/jobs,https://hackerone.com/bumble?view_policy,,
localdigital.gov.uk,true,true,200,,,"https://hackerone.com/2a42b991-30b3-419b-853a-2b9895da2a1e/embedded_submissions/new, https://www.localdigital.gov.uk/contact/",,2023-03-31T22:59:00.000Z,https://dluhcdigital.blog.gov.uk/jobs/,https://www.gov.uk/guidance/vulnerability-disclosure-policy-mhclg,en,
eifel.cloud,true,true,200,,,https://hackerone.com/nextcloud,,2021-12-31T23:00:00.000Z,,https://hackerone.com/nextcloud,,
dreft.com,true,true,200,,,https://hackerone.com/proctergamble,,,,,,
londis.co.uk,true,true,200,,,https://hackerone.com/tesco/reports/new,,,,https://hackerone.com/tesco,en,
linkedin.nl,true,true,200,,https://www.linkedin.com/.well-known/security.txt,"https://hackerone.com/linkedin, https://www.linkedin.com/help/linkedin/answer/62924",,,,https://hackerone.com/linkedin?view_policy=true,,
We thought this was quite interesting; It shows that website owners are keen on getting issues reported quickly using third-party services like HackerOne and BugCrowd.
For BugCrowd, there were 40 websites with points of contacts.
Bonus: Moz Top 500
The Mozilla Top 500 is a list of 500 of the most popular websites on the Internet. The ranking is based on the Domain Authority of a website, which is a metric for search engine ranking score developed by Mozilla. It too was put through our tool. This list most likely includes websites that many readers frequently visit.
The results show that 77 (15.4%) have a security.txt file, while 423 (84.6%) do not.
Big companies
FTSE 100
The results show that 5 websites have a security.txt file, while 95 do not. All five companies provide a security contact address but did not supply a vulnerability disclosure policy.
Below is a list of companies in no particular order, but well done to them:
www.sage.com
www.dssmith.com
www.glencore.com
www.schroders.com
www.prudentialplc.com
The screenshot below shows a company (centrica.com) using a comment and a list:
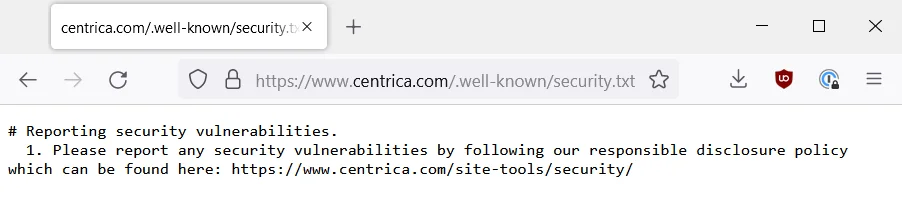
According to the standard, instead of using # comment and a 1. list, they should be using a Policy: field name with a value of a URL to their disclosure policy (which they already have). We actually saw quite a few similar results across all the groups. Nevertheless, the tool does NOT parse pages like this.
S&P 500
The results show that 18 (3.6%) have a security.txt file, while 472 (96.4%) do not. All companies provide a valid point of contact address. But only 10 actually provide a link to a vulnerability disclosure policy.
Below is a list of companies in no particular order:
adobe.com
adp.com
akamai.com
amazon.com
carmax.com
consumersenergy.com
dollartree.com
fortinet.com
hcahealthcare.com
ibm.com
intel.com
johndeere.com
linde.com
marriott.com
paypal.com
qualcomm.com
slb.com
southwest.com
The list features mostly tech companies, which is not surprising.
UK Financial Industry
Note: many domains did not respond to our requests or had stale DNS records.
Unsurprisingly, only 1 (0.069%) company out of total of 1446 have a security.txt file. But upon manual review, it didn’t provide valid contact information (Contact: socREMOVETHIS@page.com). So in actual fact the result is 0.
This is rather disappointing to say the least.
Banks
For the top UK Banks, only 5 (25%) have a security.txt file, while 20 (75%) do not. All 5 have a security point of contact, but only 2 have a link to a vulnerability policy page.
Below is a list of companies in no particular order:
monzo.com
starlingbank.com
www.revolut.com
www.co-operativebank.co.uk
www.nationwide.co.uk
Summary
The survey tells us that the adoption of the security.txt file is quite slow. It is still a relatively new concept, where only a fraction (not even 1 percent) of the top million sites are using it. The same thing goes for big companies. We are also surprised to see how popular HackerOne and other bug programs are becoming for reporting security issues.
The security.txt file has only recently became part of the RFC standard. However, there is no requirement for having one, but by having one, it does show a willingness to make security researcher’s jobs a lot easier.
Download
To download the latest version of the tool head over to Github page: https://github.com/markuta/go-security-txt. You can use the latest release which supports: Windows, macOS (Intel+M1), and Linux platforms without having to build it from source.
All the results can be found in the Github repo (out folder) or use these links:
- Tranco 1m list (compressed 7z ~14.2 MB)
- Moz 500 (68.2 KB)
- FSTE 100 (12.5 KB)
- S&P 500 (67.5 KB)
- UK finanical companies (263 KB)
- UK banks (2.62 KB)
- Hunting for Bitwarden master passwords stored in memory
- Security Advisory - Vulnerabilities with Crocus Iris App
- Parental Protections Pose Problems for PlusNet Pixel Patching

|
Naz is an OSCP-certified technical cyber security professional with experience in security and penetration testing, and vulnerability research. Naz has found credited vulnerabilities in hardware devices, mobile and web applications. At Red Maple he helped to deliver our cyber security consulting services, until his departure in April 2024. He still blogs on his personal blog. |




